E-mail debra@win.tue.nl
The World Wide Web contains a vast amount of information on every imaginable subject. Most of this information is very stable, but some of it is generated dynamically and therefore short-lived. The lack of a complete and usable catalog or index however makes it difficult for users to find the information they want.
This paper gives an overview of the techniques used to find information on the Web, and the search facilities based on them. A better insight in the capabilities and limitations of the different search tools can help users select the appropriate tool for each task.
Since its conception around 1990 the World Wide Web has been growing at an exponential rate (called the slow bang by Tim Berners Lee), to become the largest information space on the Internet, and probably also in the World. The loose network structure that makes it easy for individual organizations to become part of the Web and provide information on their own server is also the source of the largest information nightmare of the world: for many users it has become very difficult, if not impossible, to find information on the Web, even when one knows it exists.
Information retrieval is a research field with a long history. (See [MB85] and [GS89] for an overview.) The process of finding information can be divided into three stages:
In order to answer the user's queries in a timely fashion, most search tools use a specially prepared database instead of searching the documents on the fly. Depending on the technique used for generating this database certain types of questions can or cannot be answered. The search tools that are publicly available on the Internet use different types of databases and different techniques for accessing the documents on the Web. As a result they can answer different questions, and even on the same question they may give different answers. This paper gives an overview of the freely available search tools, the techniques used for accessing the Web and for indexing the information. It is the aim of this paper to provide the reader with a better insight in the information retrieval problem on the Web, and in the merits and limitations of the available search tools.
In this paper we will use the following example of a search: at the Eindhoven University of Technology we have developed a course on hypertext and hypermedia. The complete text of this course has been available on the Web since early 1994. It consists of 163 small documents, with many links between them. The address is http://wwwis.win.tue.nl/2L670/. We describe our experiences with finding the first page of this course using different search tools on the Web. We also describe our experience in locating the home page of the author (of the course and of this paper), Paul De Bra, and of another researcher, Ad Aerts.
The structure of this paper is as follows: in Section 2 we briefly sketch the overall hypertext structure of the World Wide Web. Section 3 describes how "robots" are used to find some, most or all documents on the Web. Section 4 describes how index databases store (descriptions of) documents and how search engines enable users to find information. This section also includes our experience in locating the hypermedia course and the two people's homepages using the most popular search tools. Section 5 describes Harvest, an example of a novel and distributed approach to solving the main problems with information retrieval on the Web. In Section 6 we give some concluding advice on which tool to use for which kind of search request.
Hypertext is defined by Shneiderman and Kearsley [SK89] as a database that has active cross-references and allows the reader to "jump" to other parts of the database as desired. This definition suits World Wide Web well: documents have active links to each other, meaning that the user can jump from one document to another by following these links. Users can also jump directly to documents by means of the name and location of a document. The Web uses Universal Resource Locators (URLs) to address documents. URLs are most useful when the user knows the location of a desired document. When searching for information one normally wants to find out the location of documents containing that information, hence URLs are the answers to queries.
Search tools have to follow links to find where the documents are, by traversing the Web. Figure 1 shows a graph structure like that of the Web. A few servers are shown, having many connections between documents on the same server, and a few connections to each other.
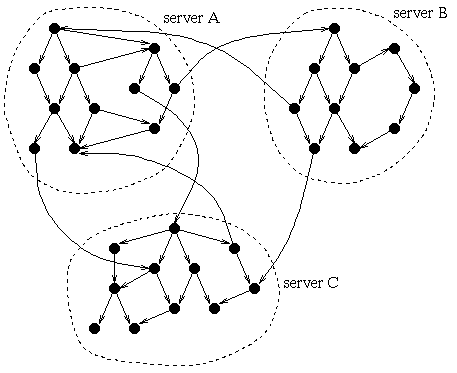
Apart from a rough idea of the graph structure of the Web, Figure 1 also illustrates that although the depicted graph is completely connected it is impossible to reach all the nodes of the graph from a single starting point and by following links forwards. Even when it is possible to jump back to nodes that were visited earlier, a feature offered by most Web browsers, some nodes still remain unreachable. The same problem exists in the "real" Web: the entire Web cannot be reached by following links alone. Different "tricks" are needed in order to find a set of starting points from which the entire Web can be reached.
A lot of information on the Internet is available from ftp servers (ftp means file transfer protocol), and around 1991 and 1992 the Gopher servers also became popular. Ftp servers are strictly hierarchical because they access files directly from the (Unix) file system. Gopher servers are also hierarchical, using a menu system, but they may also contain menu items that point to information on other servers. Finding all documents or files on such hierarchical servers is much easier (once you know where the servers are) than finding the documents on a World Wide Web server.
The RBSE spider project [E94, E94a] from the University of Houston has investigated the World Wide Web structure by counting the number of links from and to each document. The more links there are to a document the easier it is to find that document by following links. Even when visiting only a small part of the Web, chances are that a pointer to such a document is found. When there are many documents to which there are only a few links, a large part of the Web must be visited before a pointer to such documents is found. The RBSE spider found that for 59% of the documents on the Web there is only one link pointing to them, and to 96% there are no more than five links. This means that most documents on the Web are hard to find by means of navigation.
Browsing, or "surfing" the Web, consists of starting at a known (URL of a) document and following links to other documents at will. A (graphical) browser program shows where anchors to links are in a document, for instance by underlining them and/or displaying them in a different color than the rest of the document. Documents on the Web are written using HTML, the HyperText Markup Language. Links are embedded in documents using HTML anchor tags that contain the URL of the destination of the link. Users who remember URLs (or put them in a hotlist) can tell the browser to jump directly to a document with a given URL.
In order to search the Web for information, or to simply gather documents to build an index database, one needs to run a program that retrieves documents from the Web in much the same way as a surfing user retrieves documents by means of the browser. These special programs are called robots or spiders. Martijn Koster (formerly at Nexor, now at WebCrawler) maintains a list of known robots, and a mailing list for robot creators and users.
Although conceptually the robots or spiders appear to wander around the Web, they only wander virtually, because they really remain located on the same computer. Names like "WebWanderer" and "World Wide Web Worm" may suggest programs that invade computers all over the Web to extract information and send it back to their home base, but all they really do is retrieve documents from different locations on the Web to the computer they reside on. Hence they do not impose any danger like the infamous Internet Worm [D89] back in 1988.
All robots use the following algorithm for retrieving documents from the Web:
As figure 1 shows, no single starting point is sufficient for finding the whole World Wide Web. Therefore, the composition of the initial list of known URLs is an important step towards finding as much of the Web as possible. Also, when using a robot for finding information on a specific topic, an initial list of documents relevant to that topic is a big step forwards.
The World Wide Web organization maintains an official list of Web servers (at http://www.w3.org/hypertext/DataSources/WWW/Servers.html). This list contains pointers to sublists for each country. None of these lists are really complete. The official list for the Netherlands (at http://www.nic.surfnet.nl/nlmenu.eng/w3all.html) and the unofficial graphical overview, called the "Dutch Home Page" (at http://www.eeb.ele.tue.nl/map/netherlands.html/) usually contain different server addresses. Furthermore, most organizations list only one server, while they have several others that can be reached through the one listed server. As a starting point for locating most of the Web such lists are extremely valuable. Although they don't provide an address for every server, they bring a robot to the neighborhood of nearly every server on the Web.
New and exciting information often appears on servers that are not yet registered with the official or unofficial lists. In order to find this information some robot sites monitor a number of mailing lists and Usenet Netnews groups. Announcements of new services or reports from interested users often appear on netnews long before there are any links to the documents on known Web servers.
The processes of taking URLs from the list and adding new URLs to it determine the navigation strategy of the robot. If newly found URLs are always added to the same side of the list as where URLs are picked for retrieving the next document the robot navigates in a depth-first manner. If new URLs are added to one end of the list and URLs are picked from the other end the robot performs breadth-first navigation.
Most robots exhibit a behavior somewhere in between these two extremes, in order to benefit from the advantages from both strategies without suffering from their drawbacks.
Several robot-based search databases use multiple robots (sometimes called agents) in parallel, to achieve better overall retrieval performance. Although such actions to receive a larger share of the total network bandwidth are generally considered rude and unacceptable behavior, most robots make sure not to retrieve more than one document from the same server at once, or even consecutively. (The Netscape Navigator exhibits an even more rude behavior by loading in-line images in parallel, from the same server.) Using multiple agents in parallel not only speeds up the overall process, it also avoids blocking when a robot encounteres a very slow link or server.
Web server maintainers can help robot builders to avoid pitfalls like infinite loops or useless documents like the contents of a cache or mirror of another server. Most robots comply to the robot-exclusion scheme (see http://info.webcrawler.com/mak/projects/robots/norobots.html) by which all documents and/or directories listed in a robot-exclusion file (robots.txt) on the Web server are ignored (i.e. not retrieved) by a visiting robot.
Ideally a robot would load the entire Web in a relatively short period of time, to ensure that the retrieved documents are up to date, and that no recent additions are missed. Given that the Internet network will always be limited and very busy during the week, reloading the whole World Wide Web over the weekend seems like a reasonable goal. Unfortunately, no robot is able to achieve this, regardless the effort put in by its creators, in terms of computer and network hardware.
The Lycos team (formerly at CMU, the Carnegie Mellon University, but now operating as an independent company) has been retrieving Web documents for over a year, thereby incrementally building and rebuilding an index database. During that period their robots have found an ever increasing number of documents, now getting to about 20 million, for a total of well over one hundred gigabytes of (textual) information. In order to retrieve that much information in a single weekend (of about 50 hours), the robots would need to be able to download at least 100 documents per second, at a sustained rate of over 5.5 Mbps (million bits per second). This transfer rate is currently impossible, both because of the overhead incurred by the TCP/IP protocol used on the Internet, the speed of light which limits round-trip packet times on intercontinental connections, and the numerous Web servers connected through slow data lines. Assuming that the average transfer rate obtained over the Web is around 1 Kbps per connection, a total of 5.500 simultaneous connections are needed to achieve the 5.5 Mbps transfer rate, but currently most network switches cannot handle 5.500 simultaneous TCP/IP connections.
Because of these limitations robot maintainers have taken different approaches: Lycos tries to download and reload the entire Web as often as possible, meaning every once in a few months up to about a year. WebCrawler on the other hand tries to download as much as possible, from as many different servers as possible, in a weekend's time, thereby achieving a more limited coverage, but with more up to date information.
The Web contains over one hundred gigabytes of textual information. Assuming one has that much diskspace available, it would still be impractical to search sequentially through that many gigabytes for documents about a certain topic. Therefore, index databases are built, that link topics or words directly to relevant documents.
An index database works somewhat like an inverted file. A normal text file contains lines of text. Given a line number one has easy and direct access to the words on that line. In an inverted file, given a word one has direct access to the numbers of the lines containing that word. The Web is a text database that provides easy access to the contents of a document, given its name. An index database tries to provide access to (names or URLs of) documents, given a description of their contents, e.g. a few words that must occur in the documents.
Generating index databases, both in general and for the Web, is difficult for a number of reasons:
Four of the most popular search tools on the Web use very different index databases which, combined with different techniques for filling them using robots, lead to different strengths and weaknesses:
There are many other search tools like the four mentioned above.
Sometimes a document can be described perfectly by giving a few words that must occur in them. Sometimes a number of words are used to describe a topic, and a relevant document may contain some, but perhaps not all of them. Sometimes one also knows words that should not occur in relevant documents. Search tools offer boolean combinations of words to enable the user to describe the documents she is looking for.
The search tools for the Web are quite primitive: they ask for a number of
keywords, and let the user select whether some or all should occur,
i.e. they offer a choice of boolean and and or.
Lycos, the TradeWave Galaxy, WebCrawler and the World Wide Web Worm
all offer this choice.
With Infoseek one can prepend a + or - sign to
words to indicate that they must or must not occur in documents in order
to consider them relevant.
Lycos offers more options than just and and or. A parameter can be selected to tell Lycos to match at least a certain number (between 2 and 7) of terms. With other search tools one may search for documents containing any or all of the hypermedia course's codes 2L670, INF725 and INF706, but with Lycos one can search for documents containing at least two of these three codes.
Note that none of the above systems offer a complete range of boolean formulae. Only Alta Vista lets you combine and, or and not and use parentheses to generate any boolean combination you want, for instance "(A or B) and not (C or D)".
When given several search terms (words), none of the available search tools offer the user complete control over the importance of words occurring in a certain order, or near each other, or in the same structural element of the document (except for searching within titles or URLs). However, this does not mean that the proximity of words has no influence on the documents that are found or on their ranking. Not many details about this are made public.
In order to take proximity of words into account an index database needs to know the location of words in each document. This makes the database a lot larger than without proximity. Instead of really using proximity, the Lycos system simply gives preference to discriminating words that occur close to the beginning of a document. This not only provides for a limited form of proximity, but also increases the importance given to the title of a document, without the need for analyzing the structure of the document to find out what the title is.
Some search tools provide adjacency search by using the given words as one large search term. When searching for the title of the hypermedia course this is useful, but it is not a complete replacement for proximity in general.
Infoseek offers the best possibilities to control proximity and word
order. The search term "user interface" (with quotes) means
that the two words must be adjacent to each other in the given order.
The term user-interface means that the two words should appear
in the given order, and near each other. [user interface]
means that the two words should appear near each other, but in any order.
Alta Vista uses the keyword near to indicate that two
terms should not be more than ten words apart in the document.
(Alta Vista is the only tool that actually explains what the exact meaning
of its proximity operator is.)
Not all words are equally important in a document. Even when the user provides several (four or more) meaningful words, a search engine may find many documents containing these words. In order to rank documents (from most to least relevant) the engine needs to guess which words are more important than others, both in the documents and in the user's search request.
Figure 2 below shows how words (or terms) should be weighed. Words that occur very frequently are not useful for finding relevant documents, and words that occur very infrequently may not be typical for the document either.
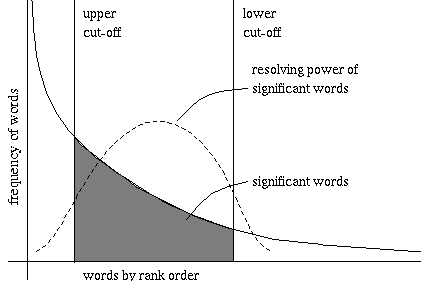
It is important to consider both the frequency of word occurrence in a single document and in the entire document database. For the hypermedia course, the codes 2L670, INF725 and INF706 are not more or less common than many others, but in the entire Web these words are ideal for discriminating between the course and other documents. When selecting a few words to characterize this document in the Web these terms are ideal, whereas to characterize this document in general (not knowing which words are typical in the Web) these words may fall below the lower cut-off because they occur too infrequently in the document. Lycos for instance has rejected the codes 2L670 and INF725 which occur only once in the first page of the course, but has kept INF706 which occurs twice.
Ideally the user would be given the option to modify the system's default weight for each of the search terms. When searching for the "Unix command cat", the word "cat" is very important because the user does not want information on other Unix commands. The system however may decide that "cat" is not an important word, because there are many documents about cats. None of the search tools for the Web offer the choice of altering the weights of search terms. But on some systems, including WebCrawler, the user can use an undocumented feature that gives a higher weight to words that are repeated in the request. So the request for the "Unix command cat" can be modified to "Unix command cat cat cat" to indicate that finding "cat" is most important.
Most search engines on the Web are not very intelligent about stripping and stemming of words, or about analyzing the structure of documents. They offer an option to find exact word matches or just substrings, putting most of this burden on the user. ALIWEB is a search engine that allows regular expressions in addition to just words. This means that ALIWEB must contain the complete text of the summaries it contains. Harvest [SBDHM94] also has the ability to perform regular expression searching, and even approximate searching, because its Glimpse index database format supports those. The on-line Fish-Search [DBP94,DBP94a,DBP94b] offers the same regular and approximate expression search, as well as a number of others.
In order to search for structural parts of documents an index database would need to analyze the HTML syntax. A few search engines, like the World Wide Web Worm and the TradeWave Galaxy, offer the option of searching document titles only, or link text only. The title is easy to detect (looking for the <TITLE> tag), and the links must be found in order to be able to find more Web documents anyway. Searching for other structural parts, like figure captions or subsection titles is not possible with any of the publicly available search engines.
As an experiment we tried to locate the hypermedia course in four different ways: using its title "Hypermedia Structures and Systems", and using three codes that exist for it: 2L670, INF725 and INF706. We also searched for the names "Paul De Bra" and "Ad Aerts".
There are two approaches to improving the results obtained from the index databases and their search tools:
Combining the forces of several search engines does not necessarily provide better results. Because each index database offers different facilities, like proximity searching, weighing keywords, specifying boolean combinations of words, or selecting exact word matching, tools that distribute queries over such databases cannot take advantage of the strength of each of these systems. However, having a single access point for all major search engines (and avoiding their commercials along the way) can be a benefit to many users.
On-line searching in a Web of 20 million documents may seem futile at first. During an on-line search each document that is examined needs to be downloaded to the site at which the search engine runs. Even for relatively well accessible servers, a transmission rate of about one small document per second is about all one can hope for. However, when starting a search from a list of URLs of documents given by one of the well known search tools, chances are that some more relevant documents can be found by examining only a few other documents, say 20 to 100. When starting with the result from a WebCrawler search one may find more documents because WebCrawler only knows about a small fraction of the Web. Furthermore, the depth-first search strategy of the fish-search complements the breadth-first strategy of WebCrawler nicely. When starting with a result from Lycos one may find more documents because Lycos may not have used the right words for indexing some other relevant documents. From Infoseek's answer to the search for the hypermedia course, listing the research group's home page with a link to the course, an on-line search using fish-search will easily find the course. From Lycos' answer which contains the first page of the course one can easily find any desired page from that course. (Pages from the course are difficult to find using Lycos, because of Lycos' intricate selection of words from documents. Pages from the course are impossible to find using Infoseek because its database does not contain them.)
The fish-search has been integrated into the Tübingen version of the Mosaic browser. As such it works like a robot in the user's machine. The fish-search also exists as a separate search tool (a CGI-script that can be installed on a Web server). When used this way the robot actually runs at the server site where it is installed, and not in the user's machine. This is most useful for users on a slow modem connection, who would rather perform the on-line search on a server machine with a fast network connection.
WebCrawler also has an experimental on-line search, which combines searching with additions to the index database. This search however is not available to the public.
The Lycos project demonstrates that even with a considerable investment in computer and network hardware it is impossible to download the entire World Wide Web onto a single site in a reasonably short period of time. Given the rate at which the Web changes and grows, and the temporary nature of a lot of information on the Web, the usability of an index database decreases significantly with each day it isn't updated. In view of the saturation of the Internet during weekdays the WebCrawler approach of downloading as much as possible during the weekend seems the least unacceptable compromise.
Distributing the download process over multiple sites, located in different parts of the world may provide a solution to the index generation problem:
Researchers from a number of institutes have initiated the Harvest project [SBDHM94]. Figure 2 below shows a simplified view of the architecture of Harvest.
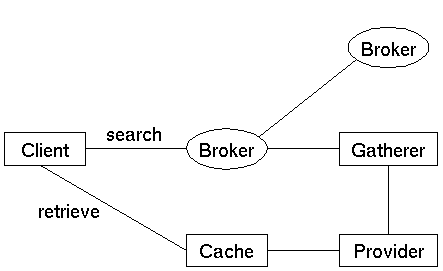
Harvest consists of the following types of parts:
It is hard to predict how many gatherers and brokers the Web will need in order to provide a decent search facility with complete coverage and good performance. A lot depends on the evolution of network bandwidth. But the ratio between the size of index databases built by gatherers to that of the complete texts is also important. A Glimpse index database as used by Harvest requires about 3 to 7% of the space used by the indexed documents. Thus, exchanging information between gatherers and brokers is much more efficient than building centralized index databases by downloading the complete documents (and one by one).
There are many freely available search tools for the Web. No single tool provides a solution for every request from every user. The main names to remember, and their strongest features are: