Most information retrieval software that is currently available
follows Luhn's assumption: the frequency of word occurrence in an article
furnishes a useful measurement of word significance.
There are a few pitfalls though:
- Words that occur very often, (and in almost all documents,) are
useless. Words that are very rare also have a low discriminating power.
- Suffixes must be stripped. But beware: the suffix "ual" may be
removed from "factual", but not from "equal". Determining the right
context for removing a suffix is difficult.
- Words must be stemmed. Two words like "absorb" and "absorpt"
have the same stem, and are thus equivalent. But beware: words like
"neutron" and "neutralize" also have the same stem, but are not equivalent.
- A thesaurus of synonyms may be used. But with words having several
meanings, another word may be a synonym for one meaning of the word but
not of the other.
- When searching for several words, the user may find one word more
important than another, while the system would rank them differently
because of their discriminating power.
Stripping, stemming and looking for synonyms must be done both on the
words in the search string and on the words in the documents.


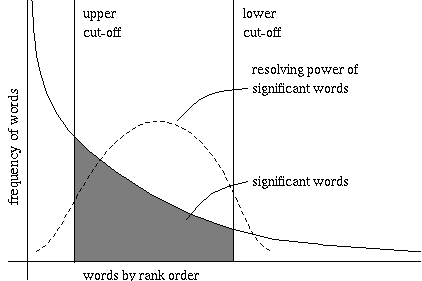
The figure below (taken from Rijsbergen's book) shows a plot of the
hyperbolic curve relating the frequency of occurrence of words to their
rank order. Words that occur very frequently (more than the upper cut-off)
are not useful for discriminating relevant from non-relevant documents.
Words that occur in very few documents are also not very useful for most
queries. (Not many queries will ask for them.)